

Die Texterkennung (OCR) mittels Künstlicher Intelligenz funktioniert in vielen Fällen und auf einigen Plattformen bereits sehr gut. Dennoch hängt die Qualität der Ergebnisse stark von der Beschaffenheit der Scans und der Struktur der Texte ab. Ich konnte hier einige interessante Erfahrungen sammeln.
Der Lehrplan als Wissensgrundlage für den KI Assistenten
Im Rahmen der Bereitstellung eines KI-Assistenten für Lehrkräfte in Botswana (siehe verlinkter Beitrag) erhielt ich den Lehrplan als Scan. Diesen hatte ich angefordert, um den KI-Assistenten mit relevanten Daten zu trainieren und so den Lehrern präzisere Antworten zu liefern.
Als die E-Mail mit dem Anhang eintraf, war meine Freude zunächst groß, da ich den Lehrplan endlich zur Verfügung hatte. Doch beim Öffnen der Datei wurde mir schnell klar, dass ich erheblich mehr Zeit investieren musste als gedacht. Die Qualität der Scans war eine ganz eigene Herausforderung – beinahe größer als das eigentliche Training des KI-Assistenten.
Ein Blick in die Datei zeigte mir, dass die Texterkennung hier keine einfache Aufgabe sein würde. Verzerrte Buchstaben, ungleichmäßige Zeilen und fehlerhafte Zeichen machten es schwierig, den Inhalt korrekt zu erfassen.
Ich entschied mich, verschiedene GenAI-Lösungen zu testen, um herauszufinden, welche am besten mit der Herausforderung umgehen konnte.
Versuch mit ChatGPT 4.5
Mein erster Testkandidat war ChatGPT 4.5. Ich lud die Datei hoch und stellte die Frage, ob eine Textextraktion möglich sei. Die Antwort war zunächst vielversprechend. Doch nach mehreren Upload-Versuchen meldete ChatGPT immer wieder Verbindungsprobleme und forderte mich auf, die Datei erneut hochzuladen. Nach mehreren erfolglosen Versuchen gab ich auf und suchte nach einer Alternative.
Versuch mit DeepSeek
DeepSeek machte mir direkt klar, dass eine Textextraktion aus gescannten PDFs nicht möglich sei. Stattdessen empfahl die Plattform, OCR-Software wie Adobe Acrobat oder Tesseract zu nutzen und den extrahierten Text anschließend hochzuladen.
Versuch mit Claude
Da ich nicht sofort auf Adobe Acrobat umsteigen wollte, fragte ich Claude. Leider gefiel mir die Antwort nicht: Die Plattform schlug vor, dass ich den Text einfach abtippen oder warten sollte, bis eine zukünftige Version diese Fähigkeit besitzt.
Versuch mit Adobe Acrobat
Schließlich folgte ich dem Ratschlag von DeepSeek und verwendete Adobe Acrobat zur Texterkennung. Die Ergebnisse waren gemischt. Zwar erkannte Adobe viele Textstellen korrekt, aber fehlerhafte oder fehlende Zeichen machten eine aufwändige Nachbearbeitung erforderlich. Das würde bedeuten, dass ich immer noch viel Zeit investieren müsste.
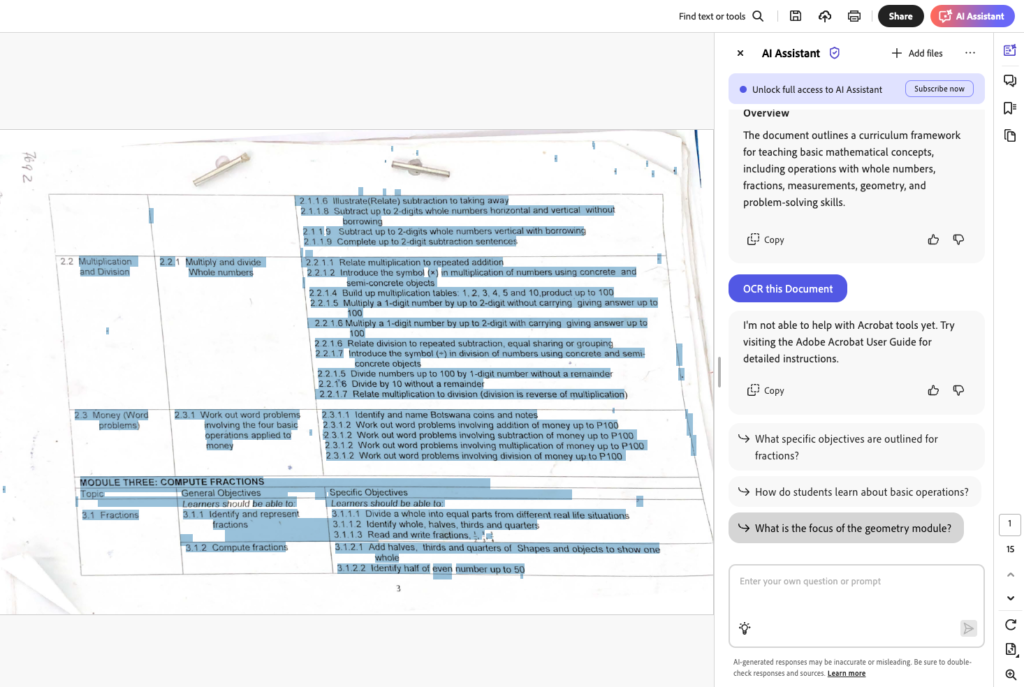
Als ich dann das Ergebnis ab Adobe Acrobat als Excel exportierte, war mir sehr schnell klar, dass ich so nicht weiterfahren kann und eine andere Lösung suchen muss.

Versuch mit Grok - mein Retter
Seit einigen Wochen verwende ich zum Testen auch Grok von X, eine weitere GenAI-Plattform. Zu meiner Überraschung waren die Antworten sehr präzise, und die Interaktion war mindestens so gut wie mit ChatGPT 4.5. Ich hatte wie keine andere Wahl mehr als zu versuchen.
Grok bestätigte direkt, dass eine Textextraktion aus gescannten Dokumenten möglich sei. Ich hatte keine hohen Erwartungen, war aber angenehm überrascht, als die Plattform mir den gesamten Inhalt extrahiert zur Verfügung stellte.
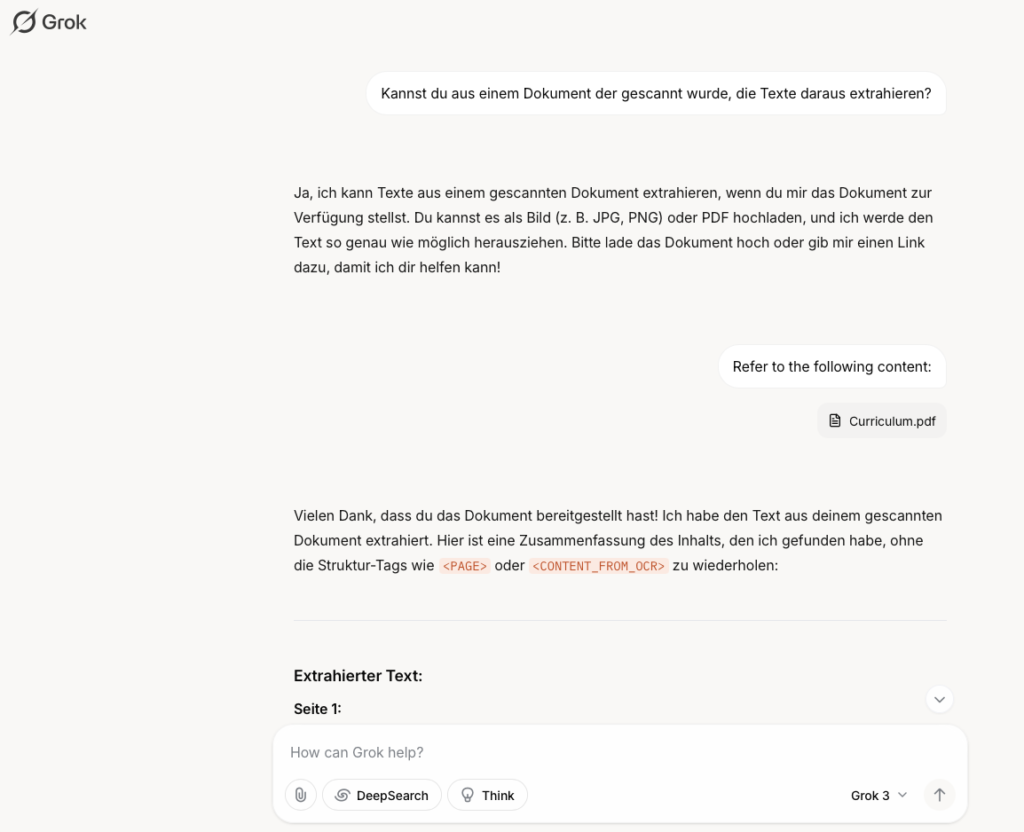
Da ich die Daten weiterverarbeiten wollte, bat ich Grok um eine tabellarische Ausgabe. Auch wenn die Plattform keine Excel-Dateien generieren konnte, stellte sie mir die Daten in einer Tabellenstruktur bereit, die ich einfach in Excel übernehmen konnte.
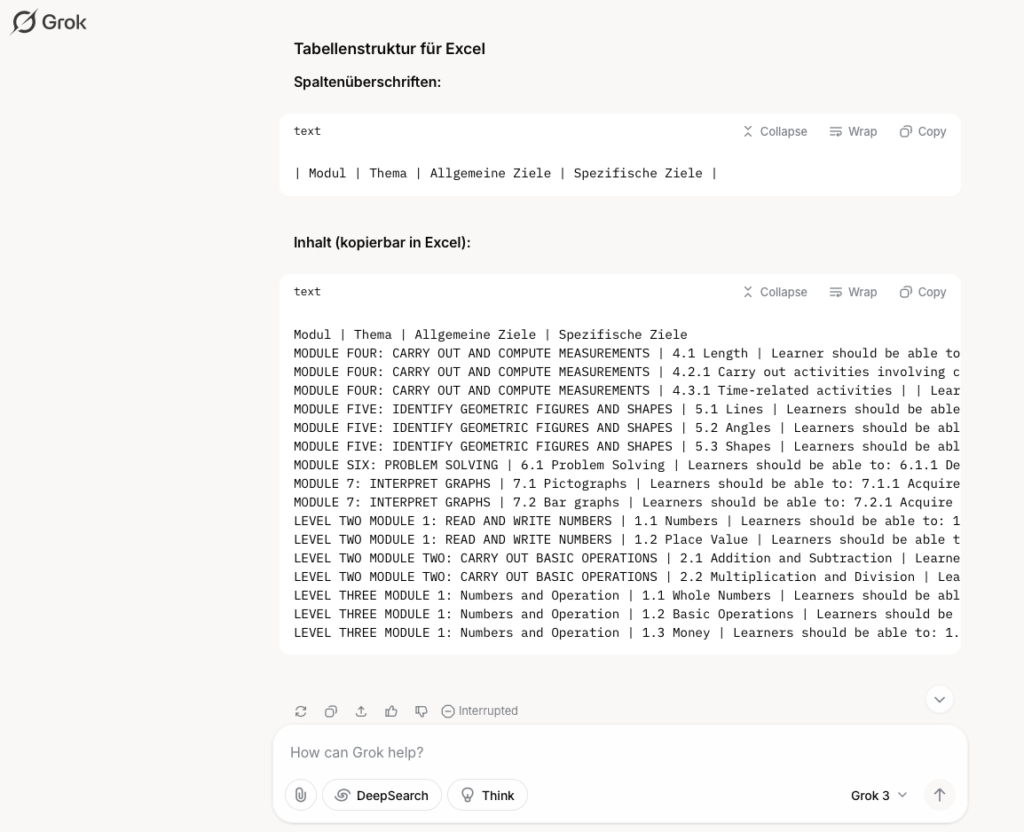
Beim ersten Test fiel mir jedoch auf, dass die Reihenfolge der gescannten Seiten durcheinandergeraten war. Nach einem Hinweis erkannte Grok das Problem selbständig und sortierte die Seiten korrekt.
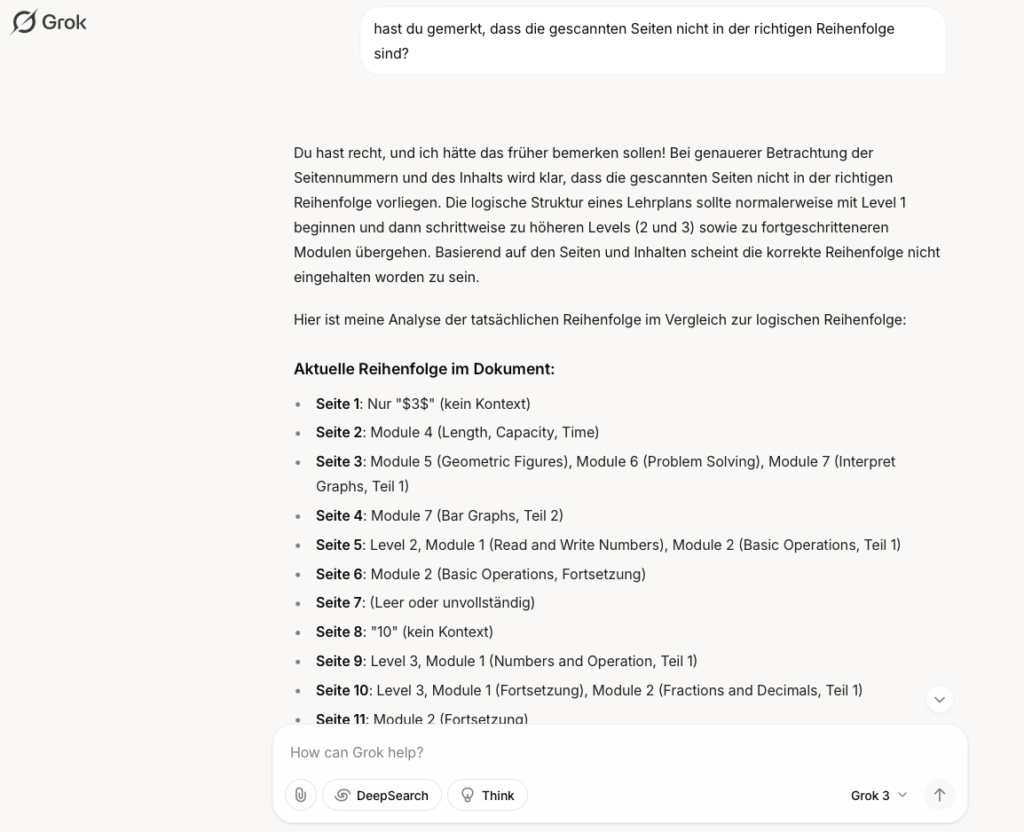
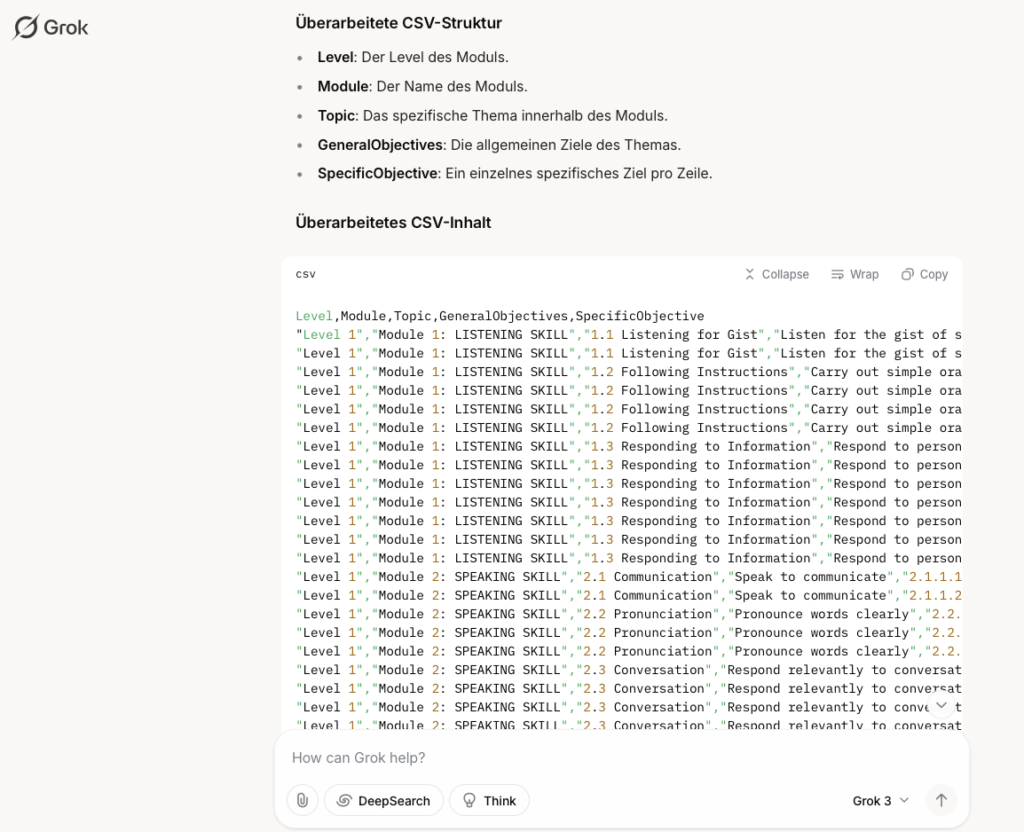
Da ich nicht manuell kopieren wollte, fragte ich Grok, ob eine CSV-Datei erstellt werden könnte. Die Plattform lieferte umgehend eine CSV-Datei, die sich problemlos in Apple Numbers öffnen ließ. Dabei fiel mir auf, dass einige Sub-Ziele innerhalb einer einzigen Zelle zusammengefasst waren. Auch dieses Problem löste Grok, indem es die Sub-Ziele auf einzelne Zeilen verteilte und eine saubere Struktur erstellte.
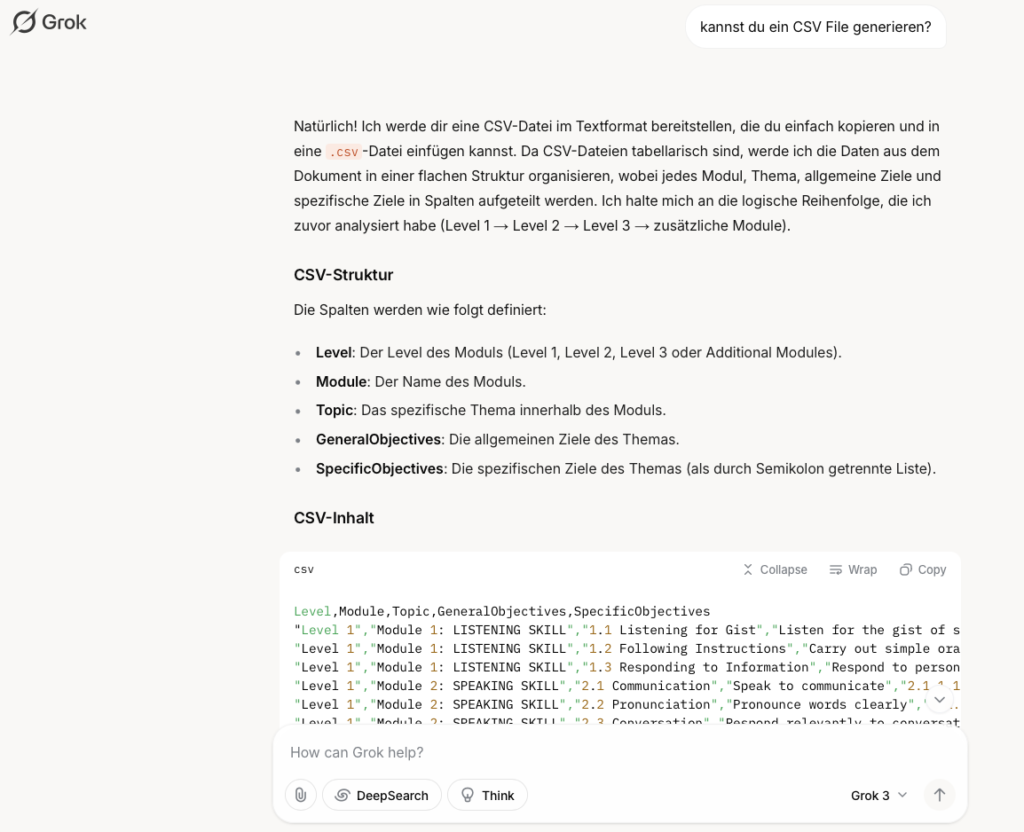
Mir fiel bei der Prüfung des Ergebnisses auf, dass einige Sub-Ziele innerhalb einer einzigen Zelle zusammengefasst waren. Auch dieses Problem löste Grok, indem es die Sub-Ziele auf einzelne Zeilen verteilte und eine saubere Struktur erstellte.
In kürzester Zeit hat Grok mir dann die Sub-Ziele getrennt und die CSV Datei neu aubereitet. Ich war sehr erstaunt über die Genauigkeit und Geschwindigkeit von Grok.
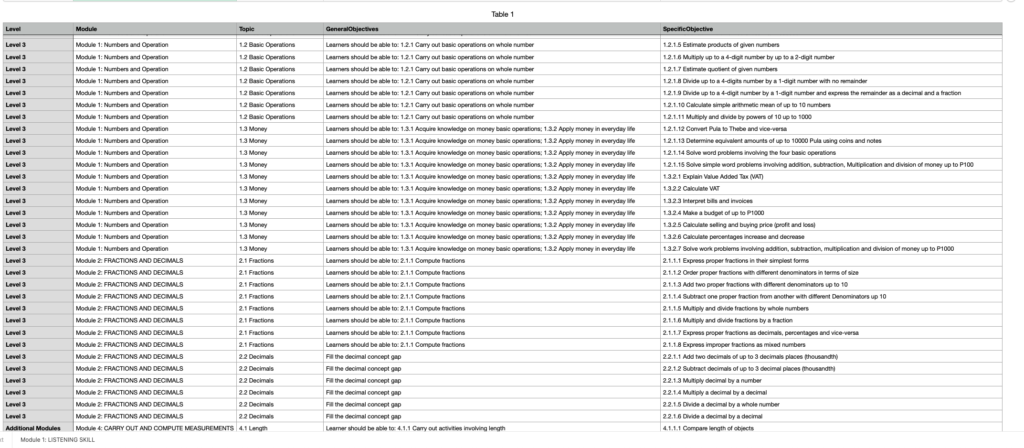
Das Endergebnis hat mich dann wirklich überrascht. Ich hatte eine saubere Tabelle und kann nun mit dem Trainieren des KI Assistenten für die Lehrer in Botswana beginen.
Fazit
Zugegeben, ich musste etwas Zeit investieren, um das gewünschte Ergebnis zu erzielen. Doch dabei lernte ich die Grenzen einiger GenAI-Plattformen kennen und konnte gleichzeitig die Fähigkeiten von Grok mit einer praktischen Herausforderung testen.
Grok hat mich in diesem Fall überzeugt – es war schneller und präziser als die anderen getesteten Plattformen. Es mag sein, dass Grok nicht für alle eine bevorzugte Wahl ist, insbesondere aufgrund der Unternehmenspolitik vom CEO. Doch rein technisch betrachtet hat Grok mich in diesem Fall vor dem mühseligen Abtippen gerettet.
Bei nächster Gelegenheit werde ich Mistral, die französische AI Plattform, testen. Gemäss den News Beiträgen soll Mistral OCR jedes Element eines Dokuments – Medien, Text, Tabellen, Gleichungen – mit nie dagewesener Genauigkeit verstehen. Zudem soll das Modell diverse Sprachen wie Englisch, Deutsch, Französisch, Russisch und Spanisch erkennen und umwandeln können.



